前言 近期线上 k8s 时不时就会出现一些内部服务间的调用超时问题,通过日志可以得知超时的原因都是出现在域名解析上,并且都是 k8s 内部的域名解析超时,于是直接先将内部域名替换成 k8s service 的 IP,观察一段时间发现没有超时的情况发生了,但是由于使用 service IP 不是长久之计,所以还要去找解决办法。
复现 一开始运维同事在调用方 pod 中使用ab工具对目标服务进行了多次压测,并没有发现有超时的请求,我介入之后分析ab这类 http 压测工具应该都会有 dns 缓存,而我们主要是要测试 dns 服务的性能,于是直接动手撸了一个压测工具只做域名解析,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package mainimport ( "context" "flag" "fmt" "net" "sync/atomic" "time" ) var host string var connections int var duration int64 var limit int64 var timeoutCount int64 func main () flag.StringVar(&host, "host" , "" , "Resolve host" ) flag.IntVar(&connections, "c" , 100 , "Connections" ) flag.Int64Var(&duration, "d" , 0 , "Duration(s)" ) flag.Int64Var(&limit, "l" , 0 , "Limit(ms)" ) flag.Parse() var count int64 = 0 var errCount int64 = 0 pool := make (chan interface {}, connections) exit := make (chan bool ) var ( min int64 = 0 max int64 = 0 sum int64 = 0 ) go func () time.Sleep(time.Second * time.Duration(duration)) exit <- true }() endD: for { select { case pool <- nil : go func () defer func () <-pool }() resolver := &net.Resolver{} now := time.Now() _, err := resolver.LookupIPAddr(context.Background(), host) use := time.Since(now).Nanoseconds() / int64 (time.Millisecond) if min == 0 || use < min { min = use } if use > max { max = use } sum += use if limit > 0 && use >= limit { timeoutCount++ } atomic.AddInt64(&count, 1 ) if err != nil { fmt.Println(err.Error()) atomic.AddInt64(&errCount, 1 ) } }() case <-exit: break endD } } fmt.Printf("request count:%d\nerror count:%d\n" , count, errCount) fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n" , min, max, sum/count, timeoutCount) }
编译好二进制程序直接丢到对应的 pod 容器中进行压测:
1 2 # 200个并发,持续30秒 ./dns -host {service}.{namespace} -c 200 -d 30
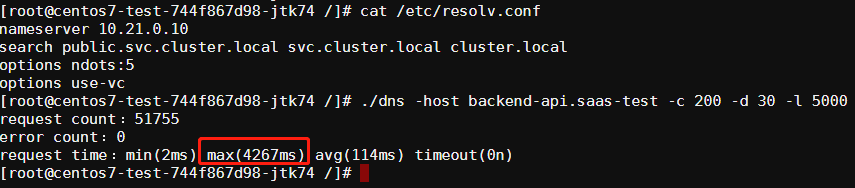
这次可以发现最大耗时有5s多,多次测试结果都是类似:
而我们内部服务间 HTTP 调用的超时一般都是设置在3s左右,以此推断出与线上的超时情况应该是同一种情况,在并发高的情况下会出现部分域名解析超时而导致 HTTP 请求失败。
原因 起初一直以为是coredns的问题,于是找运维升级了下coredns版本再进行压测,发现问题还是存在,说明不是版本的问题,难道是coredns本身的性能就差导致的?想想也不太可能啊,才 200 的并发就顶不住了那性能也未免太弱了吧,结合之前的压测数据,平均响应都挺正常的(82ms),但是就有个别请求会延迟,而且都是 5 秒左右,所以就又带着k8s dns 5s的关键字去 google 搜了一下,这不搜不知道一搜吓一跳啊,原来是 k8s 里的一个大坑啊(其实和 k8s 没有太大的关系,只是 k8s 层面没有提供解决方案)。
5s 超时原因 linux 中glibc的 resolver 的缺省超时时间是 5s,而导致超时的原因是内核conntrack模块的 bug。
Weave works 的工程师 Martynas Pumputis 对这个问题做了很详细的分析:https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts
这里再引用下https://imroc.io/posts/kubernetes/troubleshooting-with-kubernetes-network/ 文章中的解释:
DNS client (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立 fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议, connect 时并不会发包,也就不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,send 时各自发的包它们源 Port 相同(因为用的同一个 socket 发送),当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 kube-dns 或 coredns 都是访问的 CLUSTER-IP,报文最终会被 DNAT 成一个 endpoint 的 POD IP,当两个包恰好又被 DNAT 成同一个 POD IP 时,它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 dns 的 pod 副本只有一个实例的情况就很容易发生(始终被 DNAT 成同一个 POD IP),现象就是 dns 请求超时,client 默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 dns 请求有 5s 的延时。
解决方案 方案(一):使用 TCP 协议发送 DNS 请求 通过resolv.conf的use-vc选项来开启 TCP 协议
测试 修改/etc/resolv.conf文件,在最后加入一行文本:
进行压测:
1 2 # 200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
结果如下:
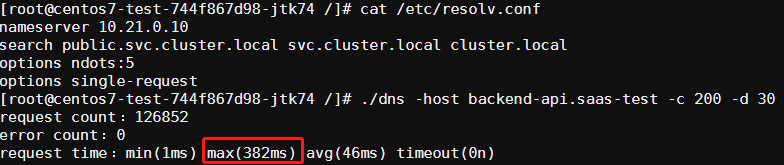
结论 确实没有出现5s的超时问题了,但是部分请求耗时还是比较高,在4s左右,而且平均耗时比 UPD 协议的还高,效果并不好。
方案(二):避免相同五元组 DNS 请求的并发 通过resolv.conf的single-request-reopen和single-request选项来避免:
single-request-reopen (glibc>=2.9) single-request (glibc>=2.10) 测试 single-request-reopen 修改/etc/resolv.conf文件,在最后加入一行文本:
1 options single-request-reopen
进行压测:
1 2 # 200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
结果如下:
测试 single-request 修改/etc/resolv.conf文件,在最后加入一行文本:
进行压测:
1 2 # 200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
结果如下:
结论 通过压测结果可以看到single-request-reopen和single-request选项确实可以显著的降低域名解析耗时。
关于方案(一)和方案(二)的实施步骤和缺点 实施步骤 其实就是要给容器的/etc/resolv.conf文件添加选项,目前有两个方案比较合适:
通过修改 pod 的 postStart hook 来设置 1 2 3 4 5 6 7 lifecycle: postStart: exec: command: - /bin/sh - -c - "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
通过修改 pod 的 template.spec.dnsConfig 来设置 1 2 3 4 5 template: spec: dnsConfig: options: - name: single-request-reopen
注: 需要 k8s 版本>=1.9
缺点 不支持alpine基础镜像的容器,因为apline底层使用的musl libc库并不支持这些 resolv.conf 选项,所以如果使用alpine基础镜像构建的应用,还是无法规避超时的问题。
方案(三):本地 DNS 缓存 其实 k8s 官方也意识到了这个问题比较常见,给出了 coredns 以 cache 模式作为 daemonset 部署的解决方案: https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/nodelocaldns
大概原理就是:
本地 DNS 缓存以 DaemonSet 方式在每个节点部署一个使用 hostNetwork 的 Pod,创建一个网卡绑上本地 DNS 的 IP,本机的 Pod 的 DNS 请求路由到本地 DNS,然后取缓存或者继续使用 TCP 请求上游集群 DNS 解析 (由于使用 TCP,同一个 socket 只会做一遍三次握手,不存在并发创建 conntrack 表项,也就不会有 conntrack 冲突)
部署 获取当前kube-dns service的 clusterIP 下载官方提供的 yaml 模板进行关键字替换 1 2 3 4 5 6 wget -O nodelocaldns.yaml "https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml" && \ sed -i 's/__PILLAR__DNS__SERVER__/10.96.0.10/g' nodelocaldns.yaml && \ sed -i 's/__PILLAR__LOCAL__DNS__/169.254.20.10/g' nodelocaldns.yaml && \ sed -i 's/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml && \ sed -i 's/__PILLAR__CLUSTER__DNS__/10.96.0.10/g' nodelocaldns.yaml && \ sed -i 's/__PILLAR__UPSTREAM__SERVERS__/\/etc\/resolv.conf/g' nodelocaldns.yaml
最终 yaml 文件如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 apiVersion: v1 kind: ServiceAccount metadata: name: node-local-dns namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: v1 kind: Service metadata: name: kube-dns-upstream namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNSUpstream" spec: ports: - name: dns port: 53 protocol: UDP targetPort: 53 - name: dns-tcp port: 53 protocol: TCP targetPort: 53 selector: k8s-app: kube-dns --- apiVersion: v1 kind: ConfigMap metadata: name: node-local-dns namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: Corefile: | cluster.local:53 { errors cache { success 9984 30 denial 9984 5 } reload loop bind 169.254.20.10 10.96.0.10 forward . 10.96.0.10 { force_tcp } prometheus :9253 health 169.254.20.10:8080 } in-addr.arpa:53 { errors cache 30 reload loop bind 169.254.20.10 10.96.0.10 forward . 10.96.0.10 { force_tcp } prometheus :9253 } ip6.arpa:53 { errors cache 30 reload loop bind 169.254.20.10 10.96.0.10 forward . 10.96.0.10 { force_tcp } prometheus :9253 } .:53 { errors cache 30 reload loop bind 169.254.20.10 10.96.0.10 forward . /etc/resolv.conf { force_tcp } prometheus :9253 } --- apiVersion: apps/v1 kind: DaemonSet metadata: name: node-local-dns namespace: kube-system labels: k8s-app: node-local-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: updateStrategy: rollingUpdate: maxUnavailable: 10 % selector: matchLabels: k8s-app: node-local-dns template: metadata: labels: k8s-app: node-local-dns spec: priorityClassName: system-node-critical serviceAccountName: node-local-dns hostNetwork: true dnsPolicy: Default tolerations: - key: "CriticalAddonsOnly" operator: "Exists" containers: - name: node-cache image: k8s.gcr.io/k8s-dns-node-cache:1.15.7 resources: requests: cpu: 25m memory: 5Mi args: [ "-localip" , "169.254.20.10,10.96.0.10" , "-conf" , "/etc/Corefile" , "-upstreamsvc" , "kube-dns-upstream" , ] securityContext: privileged: true ports: - containerPort: 53 name: dns protocol: UDP - containerPort: 53 name: dns-tcp protocol: TCP - containerPort: 9253 name: metrics protocol: TCP livenessProbe: httpGet: host: 169.254 .20 .10 path: /health port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 volumeMounts: - mountPath: /run/xtables.lock name: xtables-lock readOnly: false - name: config-volume mountPath: /etc/coredns - name: kube-dns-config mountPath: /etc/kube-dns volumes: - name: xtables-lock hostPath: path: /run/xtables.lock type: FileOrCreate - name: kube-dns-config configMap: name: kube-dns optional: true - name: config-volume configMap: name: node-local-dns items: - key: Corefile path: Corefile.base
通过 yaml 可以看到几个细节:
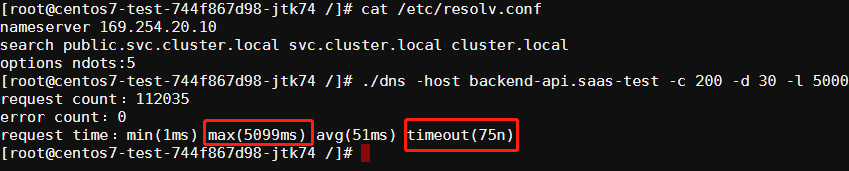
部署类型是使用的DaemonSet,即在每个 k8s node 节点上运行一个 dns 服务 hostNetwork属性为true,即直接使用 node 物理机的网卡进行端口绑定,这样在此 node 节点中的 pod 可以直接访问 dns 服务,不通过 service 进行转发,也就不会有 DNATdnsPolicy属性为Default,不使用 cluster DNS,在解析外网域名时直接使用本地的 DNS 设置绑定在 node 节点169.254.20.10和10.96.0.10IP 上,这样节点下面的 pod 只需要将 dns 设置为169.254.20.10即可直接访问宿主机上的 dns 服务。 测试 修改/etc/resolv.conf文件中的 nameserver:
1 nameserver 169.254.20.10
进行压测:
1 2 # 200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
结果如下:
结论 通过压测发现并没有解决超时的问题,按理说没有conntrack冲突应该表现出的情况与方案(二)类似才对,也可能是我使用的姿势不对,不过虽然这个问题还存在,但是通过DaemonSet将 dns 请求压力分散到各个 node 节点,也可以有效的缓解域名解析超时问题。
实施 方案(一):通过修改 pod 的 template.spec.dnsConfig 来设置,并将dnsPolicy设置为None 1 2 3 4 5 6 7 8 9 10 11 12 13 template: spec: dnsConfig: nameservers: - 169.254 .20 .10 searches: - public.svc.cluster.local - svc.cluster.local - cluster.local options: - name: ndots value: "5" dnsPolicy: None
方案(二):修改默认的cluster-dns,在 node 节点上将/etc/systemd/system/kubelet.service.d/10-kubeadm.conf文件中的--cluster-dns参数值修改为169.254.20.10,然后重启kubelet 1 systemctl restart kubelet
注:配置文件路径也可能是/etc/kubernetes/kubelet
最终解决方案 最后还是决定使用方案(二)+方案(三)配合使用,来最大程度的优化此问题,并且将线上所有的基础镜像都替换为非apline的镜像版本,至此问题基本解决,也希望 K8S 官方能早日将此功能直接集成进去。